

-
首页
-
产品中心
物联感知产品
物联网行业产品
物联通信产品
商用产品
云端产品
-
解决方案
组网解决方案
平台解决方案
低速无人驾驶
行业资讯
- · “无人驾驶、有人运营”困局何解?来电岛:自动补能+智能运营+城市成网
- · 无人配送车“遍地跑”的时代,正从山东加速到来
- · 「视觉原生」破局:视启未来的隐空间世界模型,与物理世界AI的OS野心
- · 自动驾驶下半场:无人物流一场押注生态的“生死赌局”
- · 空港“无人之境”:2025年中国机场无人驾驶落地纪实
- · 智能汽车第三轮竞赛:AI 编程决定下一代定义权
- · 智能传感领域博士李文荣获加拿大院士称号
- · 为自动驾驶注入中国基因:全球首个中国城市场景资源包上线CARLA
- · 无人配送进入‘系统对抗’深水区:三巨头疯狂卡位供应链、产能与运营
- · 斑陌易行硅谷发布三大核心技术及T6无人配送机器人,开启“真端到端”商用新时代
技术应用
- · 无人环卫——在“厘米级贴边”与“全天候作业”间寻找平衡
- · 港口室外AGV导航技术场景适配与落地优化方案解析
- · 双剑合璧:Meteor与Genario如何斩断自动驾驶的“长尾”
- · 一文读懂自动驾驶数据闭环:从概念到实践
- · 智慧公交与自动泊车——“人-车-路-云”深度协同的出行新范式
- · 封闭与半封闭园区自动化——从厂区物流到无人矿卡的车路云实践
- · 从PTP到gPTP:时间同步技术进化,为无人驾驶安全驶入“纳秒时代”铺路
- · 高速公路与城市物流——超视距感知如何重塑货运安全与效率
- · 全息路口与智慧信号控制——路侧感知如何让红绿灯“会思考”
- · 连接真实世界与模型能力的自动驾驶持续进化机制
-
四信云
-
关于我们
关于四信
企业动态
商务合作
联系我们
-
技术支持

































连接真实世界与模型能力的自动驾驶持续进化机制
解决方案
解决方案
-
组网解决方案
-
5G+行业应用
-
工业物联网
-
智慧交通
-
智慧城市
-
新零售
-
智慧农业
-
智慧电力
-
安防监控
-
智慧环保
-
智慧水务
-
能源行业
-
智慧医疗
-
商业与金融
-
-
平台解决方案
-
供暖行业
-
智慧环保
-
-
低速无人驾驶
-
解决方案
-
行业资讯
-
技术应用
-
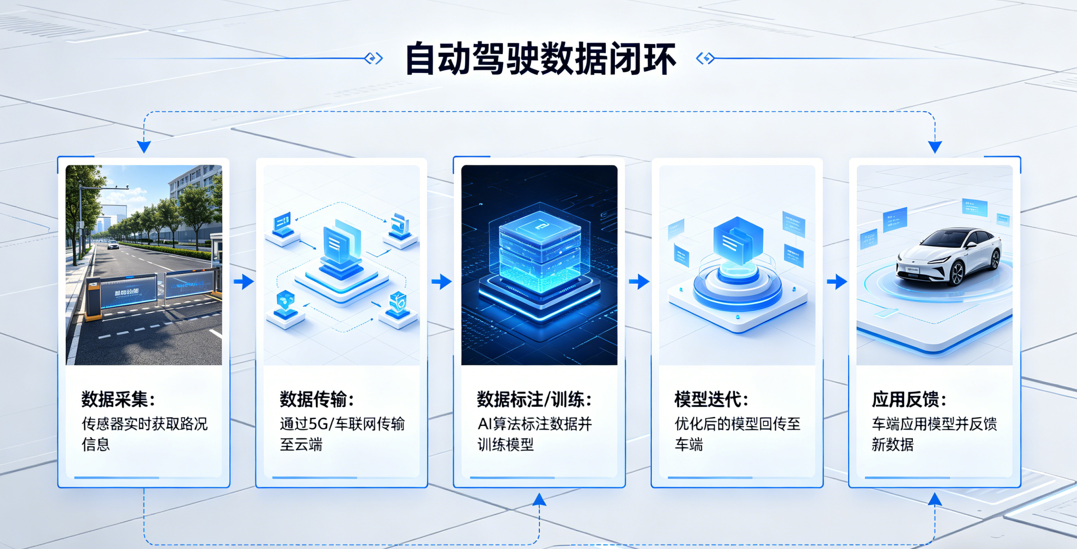
在自动驾驶领域,“数据闭环”是一个被反复提到的概念,但很多人并不清楚它究竟解决了什么问题。根本原因在于:自动驾驶系统几乎不可能在初次设计时便完全覆盖真实世界。道路环境高度开放、场景不可穷举,系统的能力只能通过持续运行与不断修正来逐步完善。而这一套持续修正的机制,便是数据闭环。
一、什么是自动驾驶中的数据闭环?
从工程实现来看,数据闭环通常包含以下环节:
车辆运行 → 场景识别 → 数据采集 → 数据处理 → 模型训练 → 验证 → 再部署
数据只是手段,真正需要修正的是系统在现实运行中暴露出的能力盲区——包括场景覆盖的不足、模型能力的缺陷,以及工程假设与真实环境之间的偏差。
二、自动驾驶的数据从哪里来?
1. 真实行驶数据仍是核心来源
目前行业内,超过80%的训练数据仍来自真实道路行驶(注:此为行业估算值,非官方统计)。主要包括测试车队采集的数据、量产车辆在限定条件下回传的数据,以及问题场景触发后的定向采集数据。真实数据的优势在于包含真实的噪声与环境不确定性,能有效暴露系统在现实中的失败模式;但其成本高、长尾场景出现概率低、数据分布不可控等缺点也十分明显。
2. 仿真与AI合成数据正在快速增长
为弥补真实数据的不足,行业普遍采用仿真环境生成数据,以及AI合成的极端或罕见场景。当前通行的做法是:真实数据用于发现问题,合成数据用于放大问题、补齐覆盖。但合成数据只能作为补充,无法替代真实数据。据佐思汽研《2025年中国智能辅助驾驶数据闭环研究报告》,2023年至2025年间,合成数据在训练数据中的占比已从20%–30%提升至50%以上,成为填补长尾场景的核心手段。
案例:理想汽车的成本变化
2023年,理想汽车全年实车有效测试里程约为157万公里,每公里成本约18元。到2025年上半年,总测试里程达4000万公里,其中实车测试仅2万公里,合成数据达3800万公里,平均每公里成本降至约0.5元,且测试场景可举一反三、完全复测。
(数据来源:理想汽车郎咸朋公开介绍)
三、为什么“有数据”不等于“有闭环”?
实践中,不少团队积累了PB级的数据,但系统能力却难以持续提升。根本原因在于:数据采集缺乏问题导向,无法精准定位模型的失败场景;数据、算法与工程流程彼此割裂;模型更新也缺少有效的验证机制。
真正有效的闭环,应当是从问题出发去采集数据,而不是先堆积数据再反推问题出在哪里。
四、行业目前的数据闭环实践现状
从行业整体看,头部自动驾驶公司已形成相对完整的数据闭环体系。数据采集越来越精细化和事件化,回传数据的比例逐渐降低,但有效数据密度显著提高;仿真与真实数据的协同使用成为主流。以小鹏汽车为例,其自建的云端模型工厂在2025年算力储备达到10 EFLOPS,全链路迭代周期缩短至平均5天,支持从云端预训练到车端模型部署的快速闭环。(数据来源:小鹏汽车公开信息)对于大多数企业而言,数据闭环仍然是拉开能力差距的关键因素之一。
五、数据闭环真正解决了什么?
数据闭环并不意味着系统不会出错,但它赋予了系统持续发现自身盲区的能力,使能力提升具有工程上的可控性,也让自动驾驶从“版本迭代”逐步走向“能力演进”。
六、总结
自动驾驶的数据闭环,本质上是一套持续修正系统认知的工程机制,它连接了真实世界与模型能力,推动系统在不断运行中自我进化。
更多详情案例,请联系我们的专家团队
厦门四信通信科技有限公司(版权所有)闽ICP备08106834号-1 ©2008-2026  闽公网安备
35021102001059号
闽公网安备
35021102001059号
关注我们











